Схема на рисунке 14.10 отражает архитектуру аналитической среды организации в более упрощенном виде, чем схема на рисунке 14.4. На ней выделено пять слоев.
Слой источников данных включает системы оперативной обработка транзакций (OLTP), поддерживающие операционную деятельность организации. Кроме того, в него могут входить различные приложения, подключаемые по API, а также датчики, внешние устройства и другие источники данных, подключаемые напрямую или с помощью сетевых протоколов.

* Управление данными в госсекторе. Навигатор для начинающих / под ред. О. М. Гиацинтова, В. А. Сазонова, М. С. Шклярук. – М.: РАНХиГС, 2022.
Слой обработки данных выделен для обозначения операций, осуществляемых в пакетном режиме (с перерывами): ETL (извлечение – преобразование – загрузка) и ELT (извлечение – загрузка – преобразование), либо в потоковом (непрерывно).
Слой хранения может включать традиционное хранилище данных – Data Warehouse (DW), хранилище больших данных – озеро данных, либо современное хранилище, объединяющее DW и озеро данных, – платформу данных.
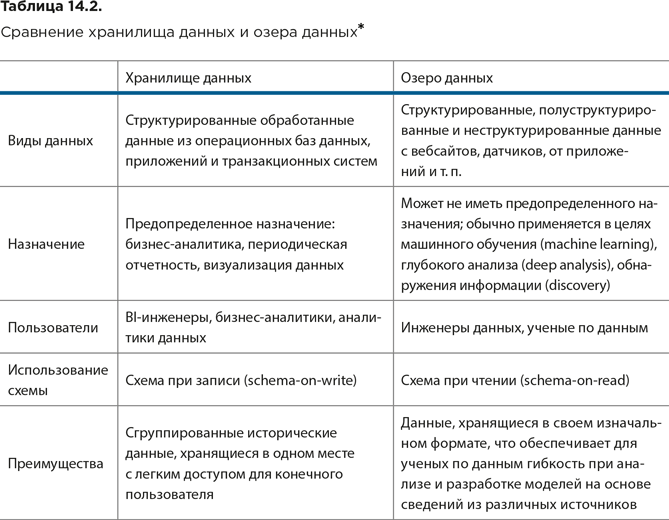
DW и озеро данных имеют схожую основную функцию (хранение данных для анализа), но различаются по своему назначению, структуре, видам хранящихся данных, а также их источникам и пользователям (см. табл. 14.2).
В DW собираются данные из бизнес-приложений для использования с конкретными целями. Перед хранением они должны быть очищены и упорядочены. При записи данные структурируют по предопределенной схеме (schema-on-write), что облегчает в дальнейшем доступ у ним.
Поскольку сведения, хранящиеся в DW, уже обработаны, их легче использовать для высокоуровневого анализа. Инструменты BI могут с ними легко оперировать, что упрощает использование хранилищ специалистами, не являющимися профессионалами в области работы с данными.
* Управление данными в госсекторе. Навигатор для начинающих / под ред. О. М. Гиацинтова, В. А. Сазонова, М. С. Шклярук. – М.: РАНХиГС, 2022.
Озеро данных – это обширное хранилище, в котором собираются необработанные данные в изначальном собственном формате. Одно из преимуществ озера данных – то, что оно может хранить данные различной структуры. Каждый сохраненный элемент данных помечен уникальным идентификатором и снабжен метаданными, чтобы при необходимости его можно было легко запросить. Данные в озере хранятся без предопределенной схемы – аналитики структурируют их только в момент чтения для конкретной задачи (schema-on-read). При построении озер данных целесообразно следовать существующим на сегодня передовым практикам[484].
Сравнительная характеристика хранилища данных и озера данных представлена в таблице 14.2.
Для наполнения хранилища применяются процессы ETL или ELT, тогда как для озера данных – преимущественно ELT или потоковая обработка данных (стриминг).

* Управление данными в госсекторе. Навигатор для начинающих / под ред. О. М. Гиацинтова, В. А. Сазонова, М. С. Шклярук. – М.: РАНХиГС, 2022.
Если говорить о построении современной платформы данных, то в настоящее время известно несколько перспективных архитектурных концепций. В частности, выделяются подходы Modern Data Architecture, Lambda Architecture и Data Mesh Architecture[485].
Modern Data Architecture объединяет преимущества DW и озера данных. При этом следует заметить, что у Modern Data Architecture отсутствует четкий дизайн с точки зрения внедрения тех или иных решений. Концепция реализации во многом зависит от видения главного инженера проекта.
Lambda Architecture – решение, построенное в том числе на концепции озера данных, которое позволяет решать задачи, связанные с обработкой в режиме реального времени, обрабатывая данные за миллисекунды.
Data Mesh Architecture активно использует стриминг-технологии, объединяет пакетную и потоковую обработки данных, а хранит данные в облаке. Благодаря этому у организаций появляется возможность анализировать данные в режиме реального времени, снизив при этом затраты на управление инфраструктурой хранилища.
Два последних слоя на рисунке 14.10 выделены для обозначения деятельности в области науки о данных (ее осуществляют ученые по данным и инженеры машинного обучения) и деятельности в области BI (ей занимаются BI-инженеры).
В таблице 14.3 описаны основные роли специалистов, работающих с аналитической средой организации.
Деятельность в рамках слоев обработки и хранения данных обычно осуществляется инженером данных. Коротко рассмотрим ее на примере операций, выполняемых в ходе процесса ETL[486].
Извлечение данных
На этом этапе данные извлекаются из одного или нескольких источников и подготавливаются к преобразованию. Отметим, что для корректного представления данных после их загрузки в хранилище из источников должны извлекаться не только сами данные, но и информация, описывающая их структуру, из которой будут сформированы метаданные для хранилища,
Преобразование данных
Чаще всего преобразование включает следующие шаги:
● Преобразование структуры данных
Данные из различных источников могут отличаться своей структурной организацией: соглашениями о назначении имен полей и таблиц, порядком их описания, форматами, типами и кодировкой данных. Перед передачей в хранилище их нужно свести к единой структуре.
● Агрегирование данных
Наибольший интерес для анализа представляют данные, обобщенные по некоторому интервалу времени, по группе клиентов или товаров. Такие обобщенные данные называются агрегированными (иногда агрегатами), а сам процесс их вычисления – агрегированием.
● Перевод значений
Часто данные в источниках хранятся с использованием специальных кодировок, которые позволяют сократить избыточность данных и тем самым уменьшить объем памяти, требуемой для их хранения. Так, наименования объектов, их свойств и признаков могут храниться в сокращенном виде. В этом случае перед загрузкой данных в хранилище требуется выполнить перевод сокращенных значений в более полные и понятные.
● Создание новых данных
В процессе загрузки в хранилище может понадобиться вычисление некоторых новых данных на основе существующих, что обычно сопровождается созданием новых полей.
● Очистка данных
Наличие «грязных» данных – одна из важнейших и трудно формализуемых проблем аналитических технологий. Очистка данных – это процедура корректировки данных, которые в каком-либо смысле не удовлетворяют определенным критериям качества, т. е. содержат нарушения структуры данных, противоречия, пропуски, дубликаты или неправильные форматы.
Загрузка данных
Процесс загрузки заключается в переносе данных из промежуточных таблиц в структуры хранилища данных. От продуманности и оптимальности процесса загрузки данных во многом зависит время, требуемое для полного цикла обновления данных в хранилище, а также их полнота и корректность.
Следует заметить, что описанный здесь спектр операций, выполняемых на этапе преобразования данных, часто расширяется. Особенно при работе с большими объемами быстро поступающих данных, когда процесс ETL заменяется на ELT (сначала данные извлекаются и загружаются в конечную систему, и лишь после этого происходит их преобразование).
В частности, в ходе преобразования может возникнуть необходимость в группировке или разгруппировке данных (объединение или разъединение данных по какому-либо признаку), нормализации (преобразование диапазона изменений числового признака в другой, более удобный для применения в процессе анализа) и квантовании (разбиение диапазона возможных значений числового признака на заданное количество интервалов и присвоение попавшим в них значениям номеров интервалов или иных меток).








